DEEP LEARNING on LIVER FIBROSIS
https://static.livemedia.gr/livemedia/documents/al22186_us75_20180323092028_op25_icim2018.pdf

DEEP LEARNING on FATTY LIVER [NAFLD]
https://static.livemedia.gr/livemedia/documents/al22186_us75_20180323092030_op26_icim2018.pdf

Như tin bài trước từ AuntMinnie, nhóm nghiên cứu Hy lạp [Greece] dẫn đầu bởi Athanasios Angelakis, PhD, từ National Technical University of Athens, đã tạo một deep neural network có thể xác định bệnh nhân có đang trong giai doạn sớm gan hóa xơ không hoặc đã hóa xơ gan rõ. Qua kiểm chứng thuật toán này có mức hoàn thiện cao hơn thuật toán [machine learning] đã công bố trên y văn.
Thuật toán đã công bố chưa có AUC [area under the curve] quá 0.87.
Nhóm Athenes, Greece dùng deep learning để phân loại cho dữ liệu của 103 bệnh nhân viêm gan mạn có sinh thiết xác chẩn giai đoạn hóa xơ gan= 62 ca có Metavir scores F0 hay F1, còn lại 41 ca có scores ít nhất là F2. Mạng deep-learning network sử dụng thông số giới tính và 4 thông số hình thái= dài cắt dọc gan T, thùy đuôi, gan P cũng như lách. Thuật tóan này sẽ đánh giá phân loại hóa xơ gan nhỏ hơn F1 hoặc lớn hơn F 2 (≤ F1 or ≥ F2).
Thông tin này đặc biệt có lợi cho người sử dụng còn thiếu kinh nghiệm về siêu âm tổng quát và siêu âm đàn hồi shearwaves.
Sau khi đánh giá chéo 10 lần, thuật toán deep learning mới về phân loại hóa xơ gan bằng siêu âm này có độ chính xác cao hơn
- độ nhạy: 90.2%
- độ chuyên biệt: 91.9%
- giá trị tiên đoán dương: 88.1%
- giá trị tiên đoán âm: 93.4%
- AUC: 0.9126
Tất nhiên bệnh nhân cần được đánh giá thêm thuật toán này.
Trong tương lai:
Bước cuối cùng của thuật toán deep-learning là cần kết hợp thêm tuổi và giới tính trong phần dân số [demographic data] nghiên cứu, và trong phần morphologic, hemodynamic, biochemical, image analysis,[hình thái, huyết động học, hóa sinh, tạo hình] và dữ liệu siêu âm đàn hồi [elastographic data]. Với thuật toán này, nên có thêm nhiều lớp [layers], không chỉ phân loại hóa xơ gan mà còn về gan thấm mỡ, cao áp tĩnh mạch cửa, và hội chứng viêm.
Đã có thuật toán và mô hình cho vấn đề gan thấm mỡ .
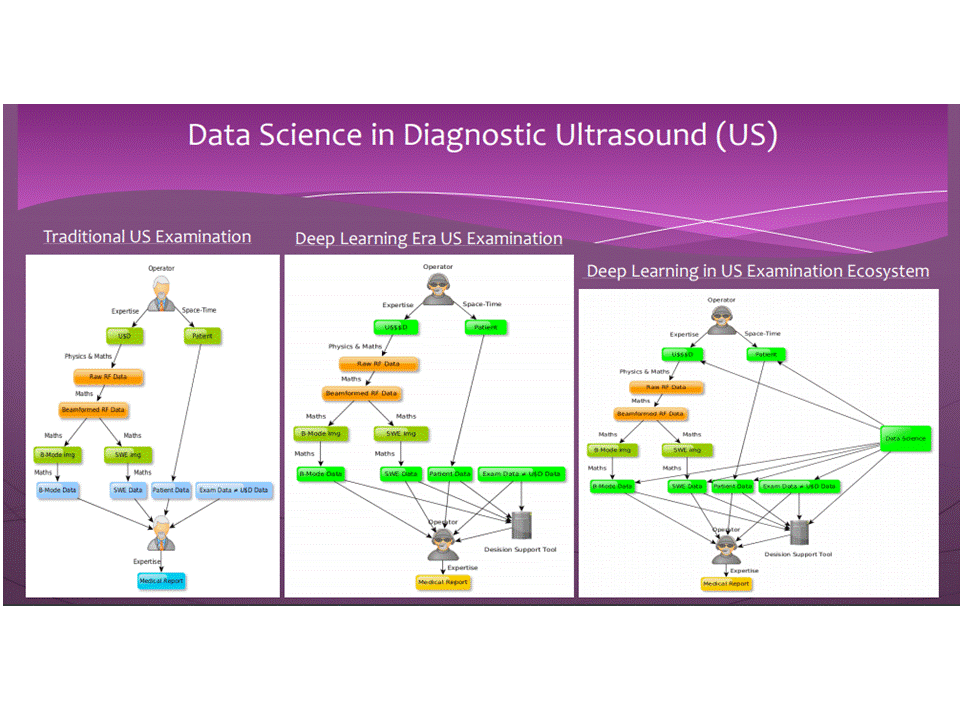
Deep learning và data science sẽ giữ vai trò quan trọng của siêu âm trong tương lai. Trong 10 năm tới hoặc ít hơn, data science sẽ được cài đặt trong máy siêu âm và sẽ sử dụng ngay trong tiến trình đánh giá siêu âm gan.
Trong tương lai:
Bước cuối cùng của thuật toán deep-learning là cần kết hợp thêm tuổi và giới tính trong phần dân số [demographic data] nghiên cứu, và trong phần morphologic, hemodynamic, biochemical, image analysis,[hình thái, huyết động học, hóa sinh, tạo hình] và dữ liệu siêu âm đàn hồi [elastographic data]. Với thuật toán này, nên có thêm nhiều lớp [layers], không chỉ phân loại hóa xơ gan mà còn về gan thấm mỡ, cao áp tĩnh mạch cửa, và hội chứng viêm.
Đã có thuật toán và mô hình cho vấn đề gan thấm mỡ .
Deep learning và data science sẽ giữ vai trò quan trọng của siêu âm trong tương lai. Trong 10 năm tới hoặc ít hơn, data science sẽ được cài đặt trong máy siêu âm và sẽ sử dụng ngay trong tiến trình đánh giá siêu âm gan.
----------------
ĐỌC THÊM=
 https://tech.fpt.com.vn/ai-machine-learning-va-deep-learning-dinh-nghia-va-cach-phan-biet-chung/
https://tech.fpt.com.vn/ai-machine-learning-va-deep-learning-dinh-nghia-va-cach-phan-biet-chung/

Không có nhận xét nào :
Đăng nhận xét